
Neon’s help for Postges’ logical replication options opens up a wide range of attention-grabbing use circumstances for real-time streaming architectures based mostly on change knowledge seize. We beforehand demonstrated learn how to use Debezium to fan out adjustments from Postgres by utilizing Redis as a message dealer.
Immediately, we’ll discover how one can leverage the Apache Kafka and Kafka Connect ecosystem to seize and course of adjustments out of your Neon Postgres database. Particularly, you’ll discover ways to stream adjustments from Postgres to Apache Kafka and course of these adjustments utilizing ksqlDB to create a materialized view that updates in response to database adjustments.
It’s attainable to run Apache Kafka, Kafka Join, and ksqlDB in your infrastructure; nonetheless, this information shall be utilizing Confluent Cloud to host these parts so we are able to deal with enabling knowledge streaming and constructing a materialized view as an alternative of managing infrastructure.
Why Apache Kafka With Postgres for Materialized Views?
Postgres is a mature and battle-tested database answer that supports materialized views, so why do we’d like messaging infrastructure like Apache Kafka to course of occasions and create a materialized view? We beforehand defined the significance of avoiding the dual-write downside when integrating your utility with message brokers, so let’s deal with the information streaming and efficiency issues as an alternative.
As a reminder, a materialized view shops the results of a question at a particular time limit. Let’s check out an instance. Think about you will have a write-heavy utility that entails two tables represented by the next SQL:
CREATE TABLE gamers (
id SERIAL PRIMARY KEY,
identify TEXT NOT NULL
);
CREATE TABLE player_scores (
id SERIAL PRIMARY KEY,
rating DECIMAL(10, 2) NOT NULL,
player_id INTEGER REFERENCES gamers(id),
CONSTRAINT fk_player
FOREIGN KEY(player_id)
REFERENCES gamers(id)
ON DELETE CASCADE
);This database accommodates a gamers desk to retailer participant info and a player_scores desk to trace their scores. You could be required to create a leaderboard desk that retains observe of every participant’s whole rating (utilizing a SUM aggregate function), retain a historical past of those adjustments, and notify subscribers about adjustments to the leaderboard in actual time.
Utilizing a materialized view is one possibility for retaining observe of the entire scores. The next SQL would create a materialized view to realize this performance in Postgres:
CREATE MATERIALIZED VIEW player_total_scores AS
SELECT
p.id AS player_id,
p.identify,
COALESCE(SUM(s.rating), 0) AS total_score
FROM
gamers p
LEFT JOIN
player_scores s ON p.id = s.player_id
GROUP BY
p.id;Maintaining the view present requires issuing a REFRESH MATERIALIZED VIEW after every insert to the player_scores desk. This might have important efficiency implications, doesn’t retain leaderboard historical past, and you continue to have to stream the adjustments to downstream subscribers reliably except you need them to ballot the database for adjustments.
A extra scalable and versatile method entails a microservices structure that makes use of change knowledge seize with logical replication to stream participant knowledge and rating occasions to an Apache Kafka cluster for processing, as outlined within the following structure diagram.

An Apache Kafka cluster is a set of brokers (or nodes) that allow parallel processing of data by downstream subscribers comparable to ksqlDB. Knowledge is organized into subjects in Apache Kafka, and subjects are break up into partitions which are replicated throughout brokers for top availability. The fantastic thing about utilizing Apache Kafka is that connectors can supply occasions from one system and sink them to different methods, together with again to Postgres if you would like! You could possibly even place Kafka in entrance of Postgres to insert rating occasions into the database in a managed method.
Get Began With Neon and Logical Replication
To get began, join Neon and create a mission. This mission will comprise the Postgres database that holds the gamers and player_scores tables:
- Enter a mission identify.
- Use the default database identify of
neondb. - Select the area closest to your location.
- Click on Create mission.
Subsequent, go to the Beta part of the Venture settings display and allow logical replication. Go to our documentation to view an entire set of logical replication guides.
Use the SQL Editor within the Neon console to create two tables within the neondb database: one to carry participant info and one other to carry rating data for gamers. Every row in player_scores accommodates a international key referencing a participant by their ID.
CREATE TABLE gamers (
id SERIAL PRIMARY KEY,
identify TEXT NOT NULL
);
CREATE TABLE player_scores (
id SERIAL PRIMARY KEY,
rating DECIMAL(10, 2) NOT NULL,
player_id INTEGER REFERENCES gamers(id),
CONSTRAINT fk_player
FOREIGN KEY(player_id)
REFERENCES gamers(id)
ON DELETE CASCADE
);Create a publication for these two tables. The publication defines what operations on these tables are replicated to different Postgres cases or subscribers. You’ll deploy a Debezium connector on Confluent’s cloud that makes use of this publication to look at adjustments within the specified tables:
CREATE PUBLICATION confluent_publication FOR TABLE gamers, player_scores;Create a logical replication slot to retain and stream adjustments within the write-ahead log (WAL) to subscribers. The Debezium connector on Confluent’s cloud will use this slot to devour related adjustments from the WAL:
SELECT pg_create_logical_replication_slot('debezium', 'pgoutput');Use the Roles part of the Neon console to create a new role named confluent_cdc. Make sure you save the password for the function someplace protected since it can solely be displayed as soon as. With the function in place, grant it permissions on the general public schema utilizing the SQL Editor:
GRANT USAGE ON SCHEMA public TO confluent_cdc;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO confluent_cdc;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO confluent_cdc;Now, you’ve bought every thing in place to start out consuming adjustments out of your gamers and player_scores tables in your Neon Postgres database.
Get Began With Apache Kafka and Debezium on Confluent Cloud
This information assumes you’re new to Confluent Cloud. In case you’re an current person, you’ll be able to modify the steps to combine together with your current environments and Apache Kafka cluster(s).
Register to Confluent Cloud and comply with the onboarding move to create a primary Apache Kafka cluster. Select the area that’s closest to your Neon Postgres database area.
As soon as your cluster has been provisioned, click on on it within the Environments display, then choose the Connectors view from the aspect menu on the subsequent web page.
Apache Kafka on Confluent helps a plethora of connectors. Many of those are based mostly on the varied OSS Kafka Connect connectors. Discover and choose the Postgres CDC Supply connector within the listing. This connector is predicated on the Debezium project we wrote about in our fan-out utilizing Debezium and Upstash Redis article.
On the Add Postgres CDC Supply connector display:
- Choose World Entry.
- Click on the Generate API key & obtain button to generate an API key and secret.
- Click on Proceed
Subsequent, configure the connection between the connector and your Postgres database on Neon:
- Database identify:
neondb - Database server identify:
neon - SSL mode:
require - Database hostname: Discover this on the Neon console. Discuss with our documentation.
- Database port:
5432 - Database username:
confluent_cdc - Database password: That is the password for the
confluent_cdcfunction you simply created. - Click on Proceed.
Configure the connector properties. The primary of those is the Kafka document key and worth codecs. Choose the next choices:
- Output Kafka document worth format:
JSON_SR - Output Kafka document key format:
JSON_SR
The JSON_SR possibility causes change occasion document schemas to be registered in your Confluent Cloud setting’s Schema Registry. That is important to working with the change knowledge occasion data, as you’ll see shortly. You possibly can consider the schema as sort info for data in your Kafka subjects.
Develop the superior configuration and set the next choices:
- Slot identify:
debezium - Publication auto create mode:
disabled - Publication identify:
confluent_publication - Tables included:
public.gamers,public.player_scores
Click on Proceed, settle for the default values for sizing and duties, and provides your connector a reputation. As soon as completed, your connector shall be proven on the Connectors display. Affirm that it’s marked as Operating and never in an error state. If the connector reviews an error, verify the configuration properties for correctness.
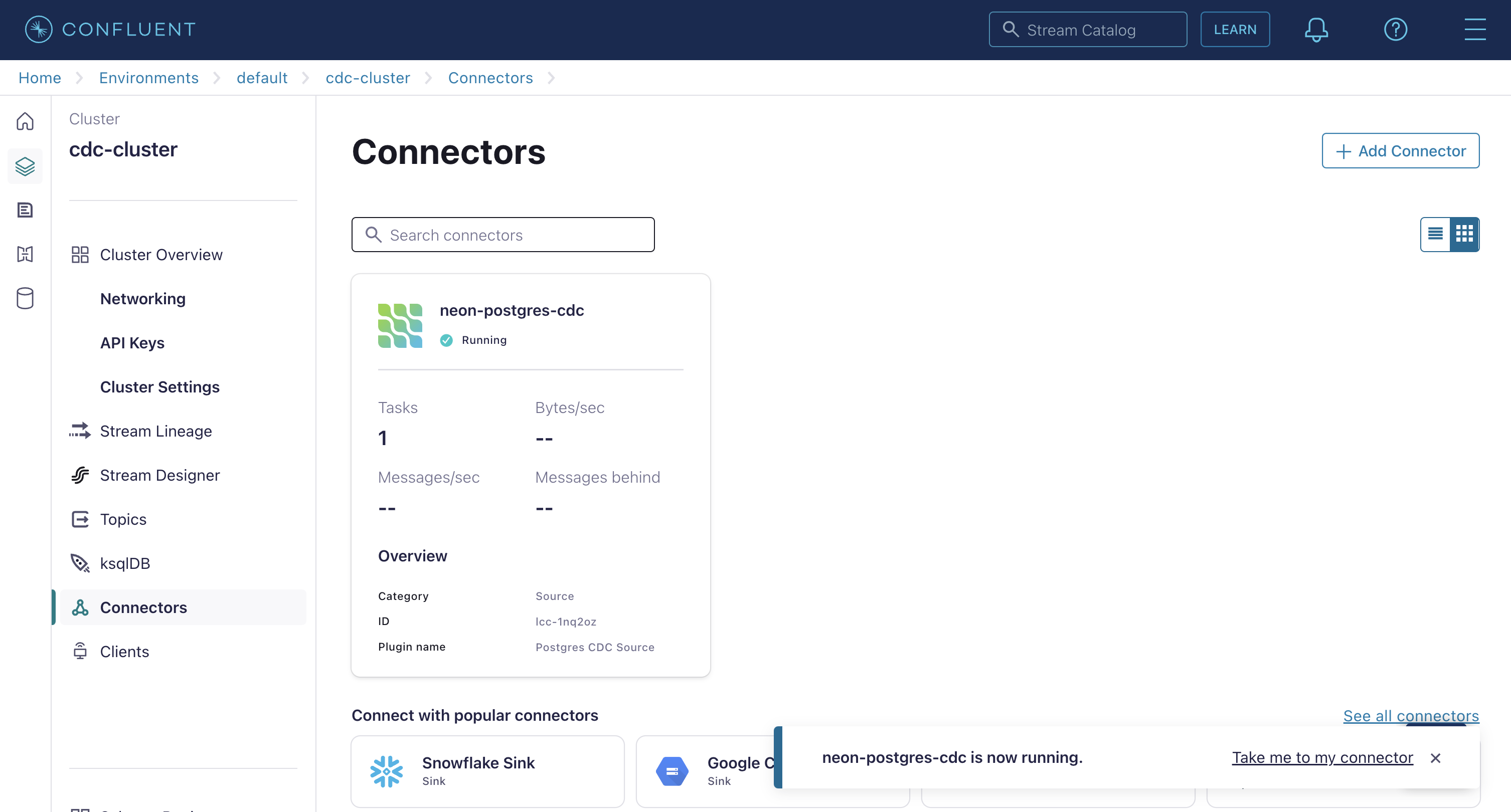
Affirm Change Knowledge Seize Is Working
Use the SQL Editor within the Neon console to insert some gamers and scores into your tables utilizing the next SQL statements:
INSERT INTO gamers (identify) VALUES ('Mario'), ('Peach'), ('Bowser'), ('Luigi'), ('Yoshi');
INSERT INTO player_scores (player_id, rating) VALUES
(1, 0.31),
(3, 0.16),
(4, 0.24),
(5, 0.56),
(1, 0.19),
(2, 0.34),
(3, 0.49),
(5, 0.71);Return to the Confluent Cloud console and choose the Subjects merchandise from the aspect menu. You will notice two subjects that correspond to your database tables.
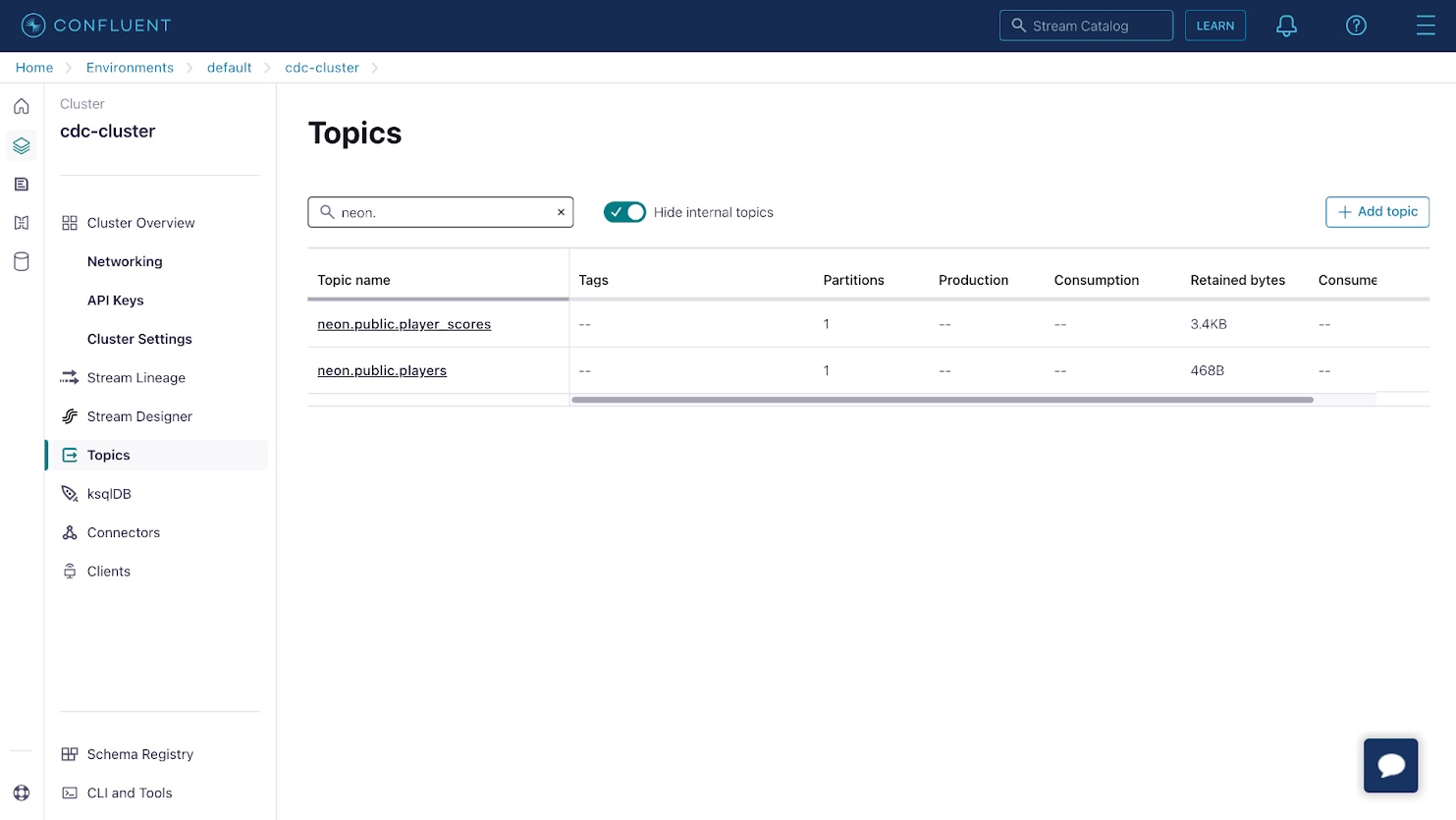
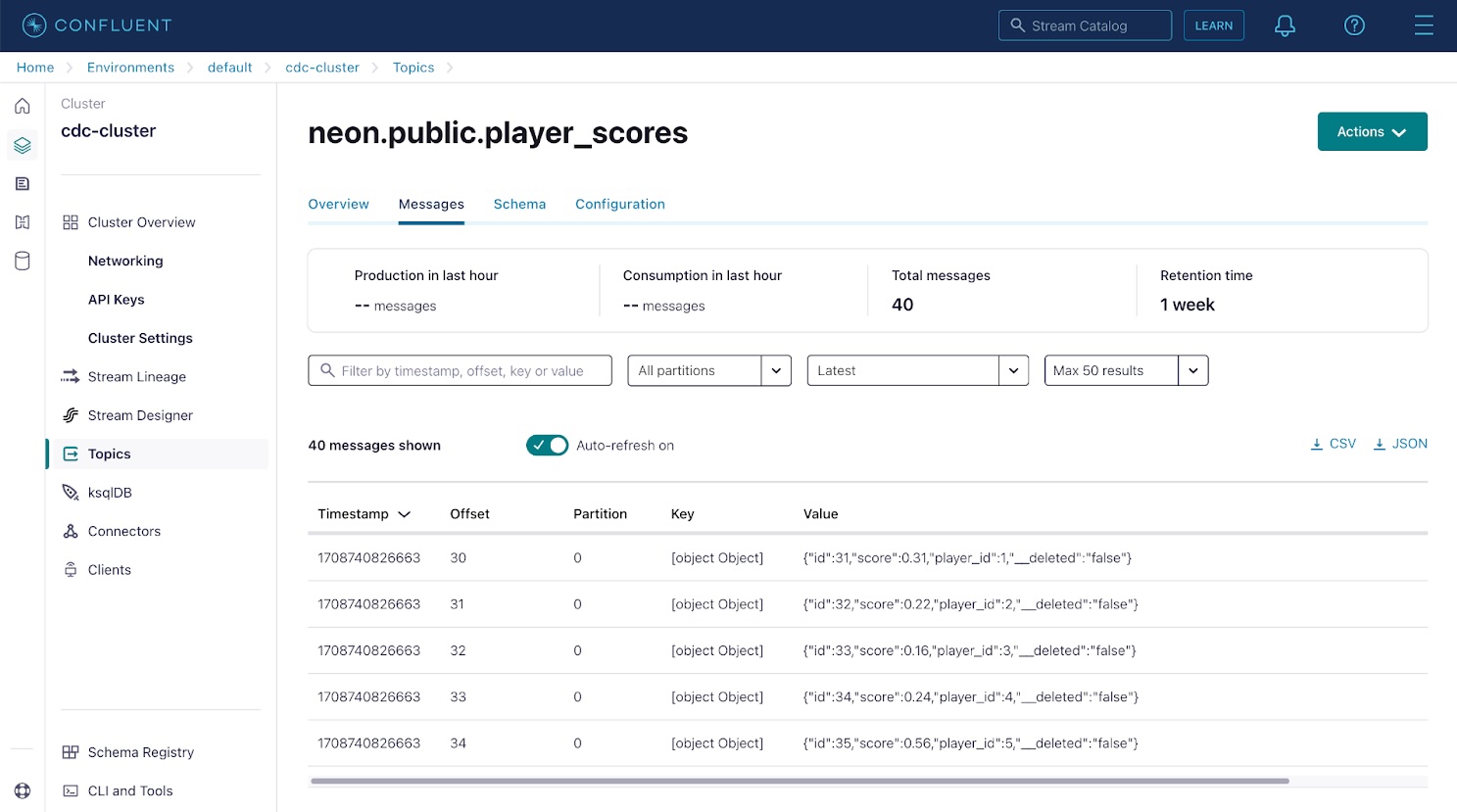
Click on on both of the subjects, then use the Messages tab to view database change occasions captured by the Debezium connector and streamed to the subject. Every message in Kafka accommodates a key and worth; on this case, these are the database row ID and row contents.
Apache Kafka makes use of partitions to extend parallelism and replicates partitions throughout a number of nodes to extend sturdiness. Since Kafka partitions are an ordered immutable sequence of messages, the offset represents the message place in its partition. Subjects in a manufacturing Kafka setting will be break up into 100 or extra partitions, if obligatory, to allow parallel processing by as many shoppers as there are partitions.
Subsequent, verify that schemas have been registered on your change data. Choose the Schema Registry from the underside left of the aspect menu within the Confluent Cloud console, and make sure that schemas have been registered for the data in your subjects.
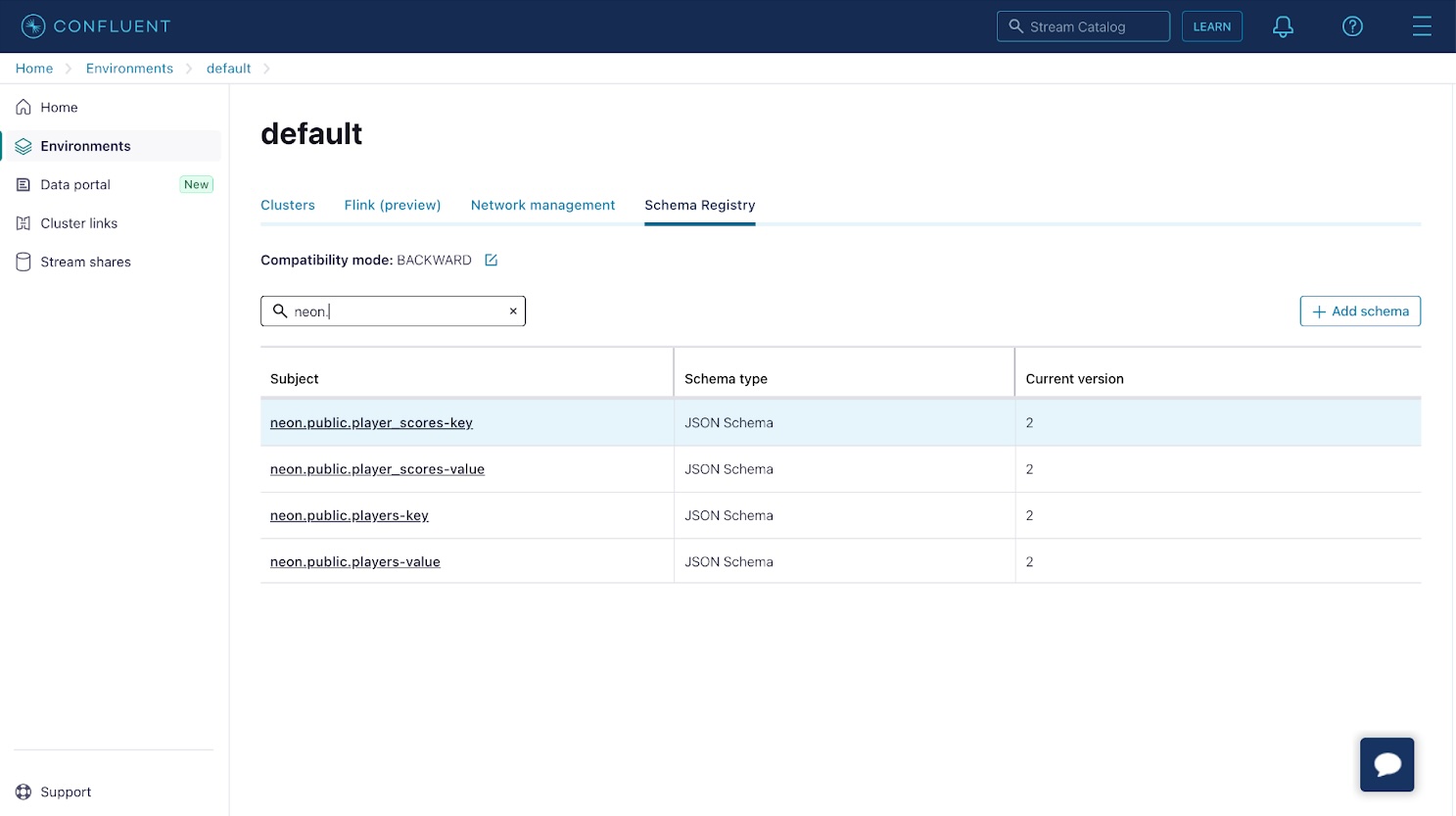
In case you click on on the schema entries with a “key” suffix, you discover that the schema merely accommodates an id property. This property corresponds to the id or main key of the database row. The schema entries with a “worth” suffix correspond to the backing desk’s schema.
Create a Materialized View Utilizing ksqlDB
With schemas and subjects containing messages in place, you should utilize ksqlDB to create a materialized view that updates in response to database adjustments.
Choose ksqlDB within the aspect menu on your cluster to provision a brand new ksqlDB occasion with World entry enabled, and use the default values for sizing and configuration. The provisioning course of can take a few minutes, so be affected person.
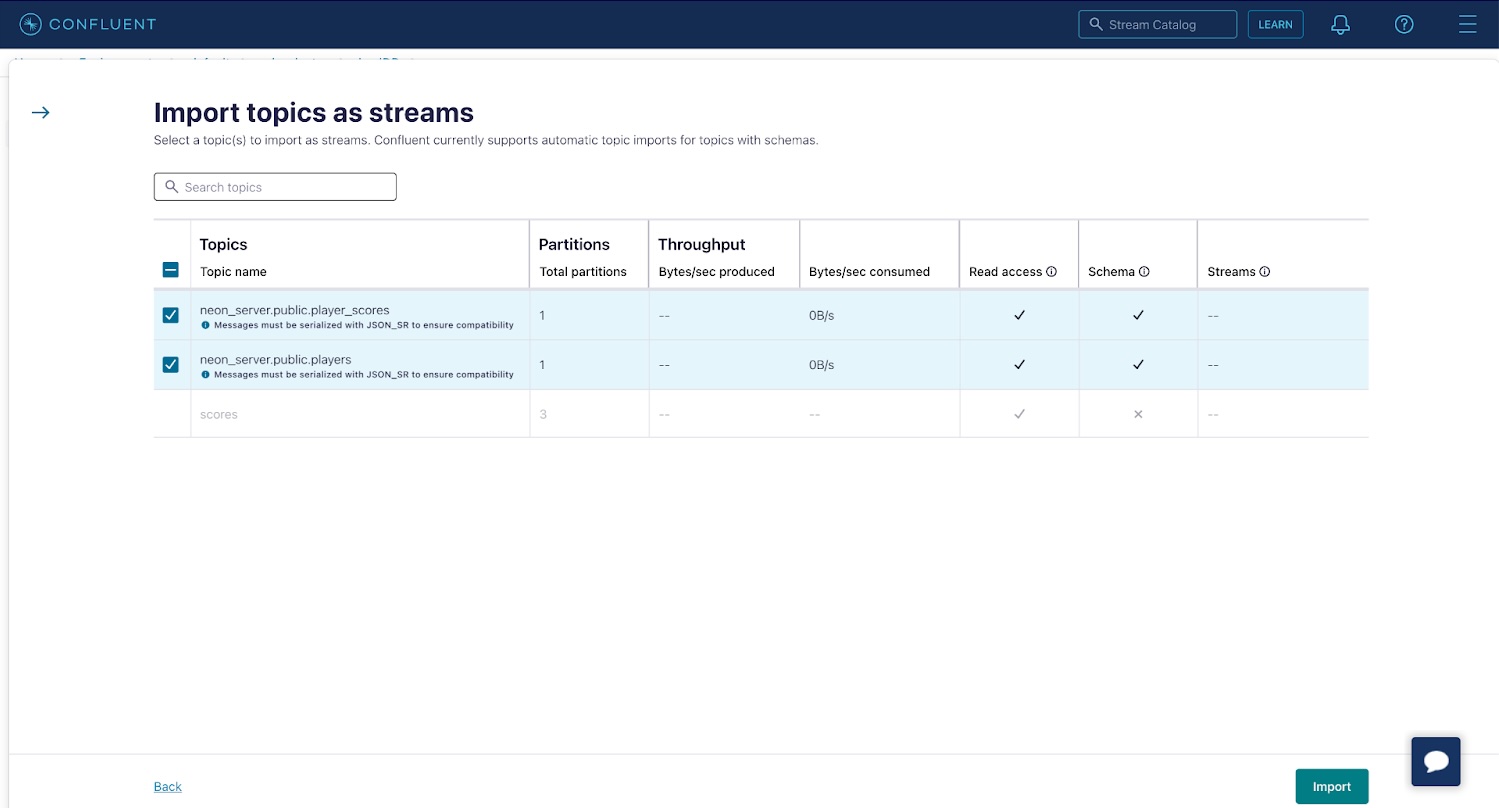
Choose your ksqlDB cluster as soon as it’s prepared, then navigate to the Streams tab and click on Import subjects as streams to import your player_scores and gamers subjects as streams in ksqlDB. Making a stream out of your matter means that you can carry out operations comparable to joins or aggregations on the information contained within the underlying matter, as you’ll see in a second. Click on Import to create the streams.
Now, use the Editor tab within the ksqlDB cluster UI to create a table named player_scores. The desk will retailer an aggregation of your system’s newest state, i.e., a materialized view. In your case, it’ll characterize the sum of the rating occasions for every participant. Paste the next question into the Editor and click on Run question.
CREATE TABLE player_scores AS
SELECT player_id, SUM(rating) as total_score
FROM NEONPUBLICPLAYER_SCORES
GROUP BY player_id
EMIT CHANGES;
This creates a desk in ksqlDB that’s repeatedly up to date in response to occasions within the NEONPUBLICPLAYER_SCORES stream. The desk will comprise a row for every participant with their distinctive ID and the sum of all related rating occasions.
Affirm the desk is working as anticipated by deciding on PLAYER_SCORES below the Tables heading and clicking Question desk. A listing of data that comprise the sum of participant scores shall be displayed.
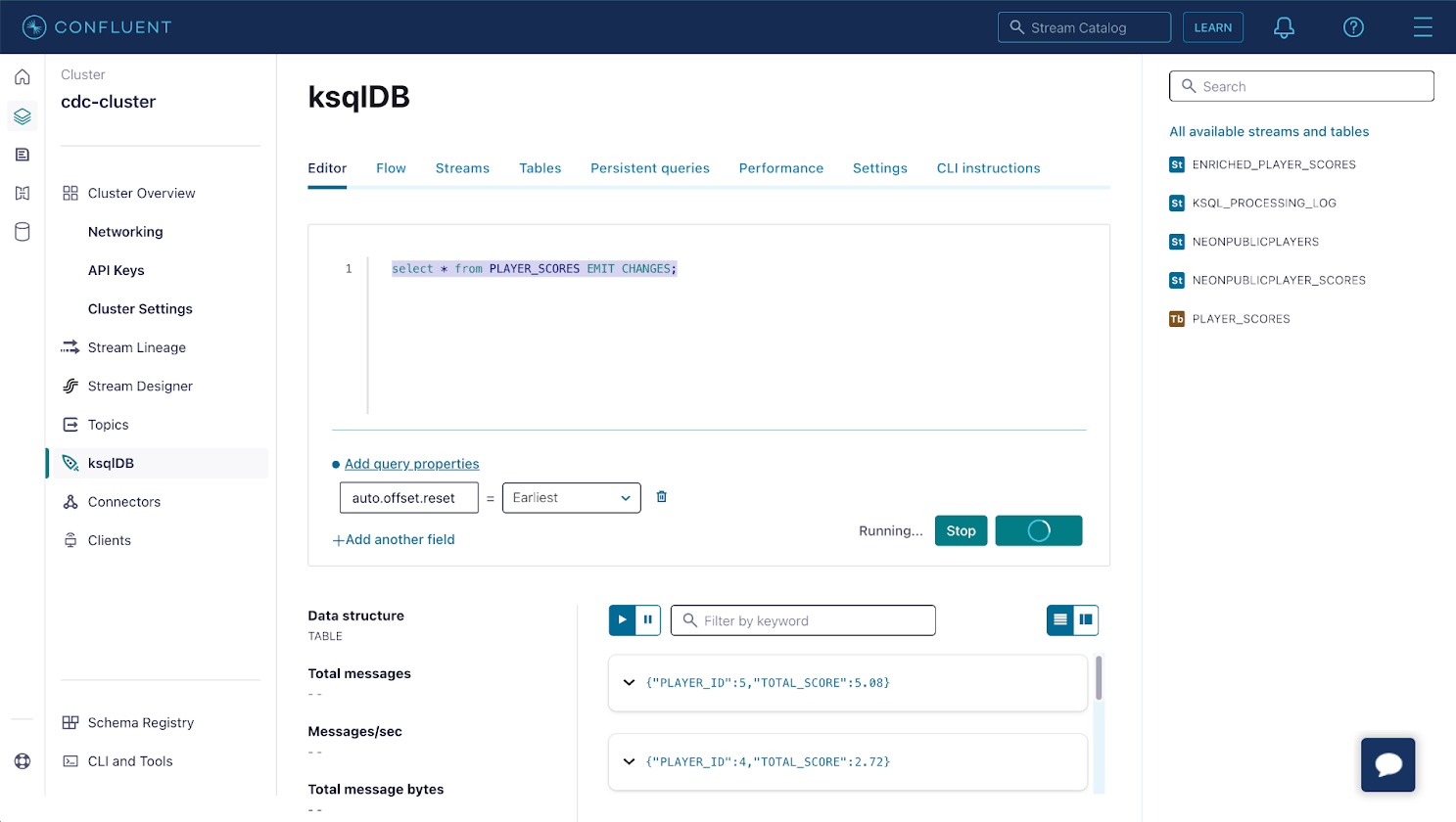
Return to the Neon console and insert extra knowledge into the player_scores desk. The materialized view will routinely replace inside a number of seconds to mirror the brand new total_score for every participant.
The materialized view will be consumed by interacting with the ksqlDB REST API. Go to the API Keys in your cluster’s UI to create an API key to authenticate in opposition to the ksqlDB REST API, and use the settings tab in your ksqlDB cluster UI to search out the cluster’s hostname.
You need to use the next cURL command to get a stream of adjustments from the desk in your terminal:
curl --http1.1 -X "POST" "https://$KSQLDB_HOSTNAME/question"
-H "Settle for: utility/vnd.ksql.v1+json"
--basic --user "$API_KEY:$API_SECRET"
-d $'{
"ksql": "SELECT * FROM PLAYER_SCORES EMIT CHANGES;",
"streamsProperties": {}
}'
This command will set up a persistent connection that streams a header adopted by adjustments as they happen within the desk in actual time. You possibly can verify this by utilizing the SQL Editor within the Neon console to insert extra knowledge into the player_scores desk and observing the up to date whole scores being streamed into your terminal:
[{"header":{"queryId":"transient_PLAYER_SCORES_7047340794163641810","schema":"`PLAYER_ID` INTEGER, `TOTAL_SCORE` DECIMAL(10, 2)"}},
{"row":{"columns":[1,4.50]}},
{"row":{"columns":[2,5.04]}},
{"row":{"columns":[3,5.85]}},
{"row":{"columns":[4,6.12]}},
{"row":{"columns":[5,11.43]}},
{"row":{"columns":[1,5.00]}},
{"row":{"columns":[4,6.80]}},
{"row":{"columns":[5,12.70]}},
{"row":{"columns":[1,5.82]}},
{"row":{"columns":[4,6.92]}}
This identical stream of occasions over HTTP will be built-in into your utility to allow real-time updates in a UI or to replace different parts in your utility structure.
Conclusion
Neon’s help for Postgres’ logical replication permits change knowledge seize and streaming database adjustments to Apache Kafka for real-time processing with ksqlDB to create enriched knowledge streams and materialized views utilizing SQL syntax. In case you’re in search of a Postgres database, sign up and try Neon without cost. Be a part of us on our Discord server to share your experiences, recommendations, and challenges.





