
The info silos drawback is like arthritis for on-line companies as a result of virtually everybody will get it as they develop outdated. Companies work together with prospects through web sites, cellular apps, H5 pages, and finish gadgets. For one motive or one other, it’s difficult to combine the info from all these sources. Knowledge stays the place it’s and can’t be interrelated for additional evaluation. That is how knowledge silos come to type. The larger what you are promoting grows, the extra diversified buyer knowledge sources you’ll have, and the extra possible you’re trapped by knowledge silos.
That is precisely what occurs to the insurance coverage firm I will discuss on this publish. By 2023, they’ve already served over 500 million prospects and signed 57 billion insurance coverage contracts. Once they began to construct a buyer knowledge platform (CDP) to accommodate such an information dimension, they used a number of parts.
Knowledge Silos in CDP
Like most knowledge platforms, their CDP 1.0 had a batch processing pipeline and a real-time streaming pipeline. Offline knowledge was loaded, through Spark jobs, to Impala, the place it was tagged and divided into teams. In the meantime, Spark additionally despatched it to NebulaGraph for OneID computation (elaborated later on this publish). Alternatively, real-time knowledge was tagged by Flink after which saved in HBase, able to be queried.
That led to a component-heavy computation layer within the CDP: Impala, Spark, NebulaGraph, and HBase.

Because of this, offline tags, real-time tags, and graph knowledge had been scattered throughout a number of parts. Integrating them for additional knowledge companies was expensive as a consequence of redundant storage and ponderous knowledge switch. What’s extra, as a consequence of discrepancies in storage, they needed to increase the dimensions of the CDH cluster and NebulaGraph cluster, including to the useful resource and upkeep prices.
Apache Doris-Primarily based CDP
For CDP 2.0, they resolve to introduce a unified answer to wash up the mess. On the computation layer of CDP 2.0, Apache Doris undertakes each real-time and offline knowledge storage and computation.
To ingest offline knowledge, they make the most of the Stream Load methodology. Their 30-thread ingestion take a look at exhibits that it could carry out over 300,000 upserts per second. To load real-time knowledge, they use a mix of Flink-Doris-Connector and Stream Load. As well as, in real-time reporting the place they should extract knowledge from a number of exterior knowledge sources, they leverage the Multi-Catalog function for federated queries.
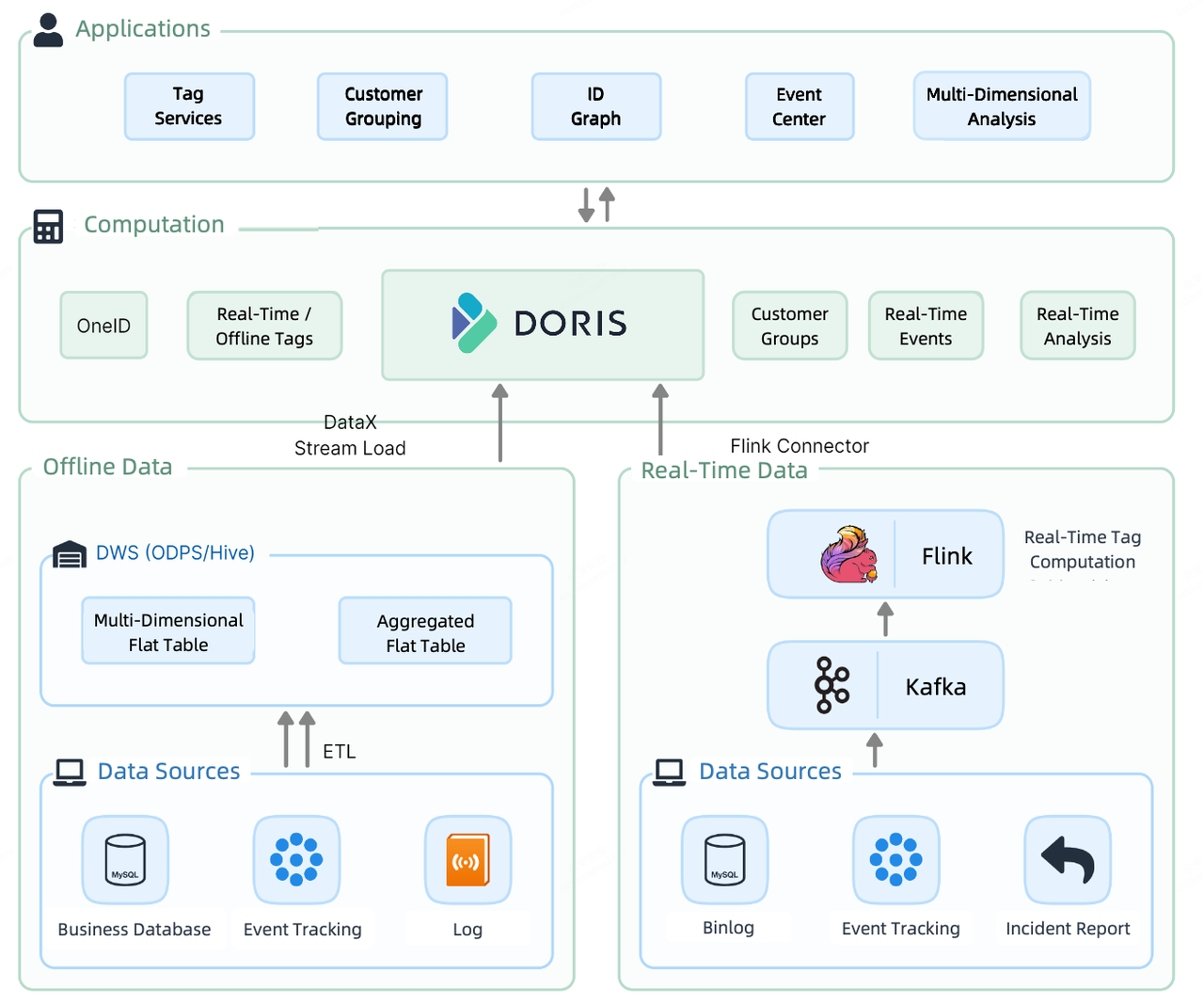
The shopper analytic workflows on this CDP go like this. First, they type out buyer data, then they connect tags to every buyer. Primarily based on the tags, they divide prospects into teams for extra focused evaluation and operation.
Subsequent, I am going to delve into these workloads and present you ways Apache Doris accelerates them.
OneID
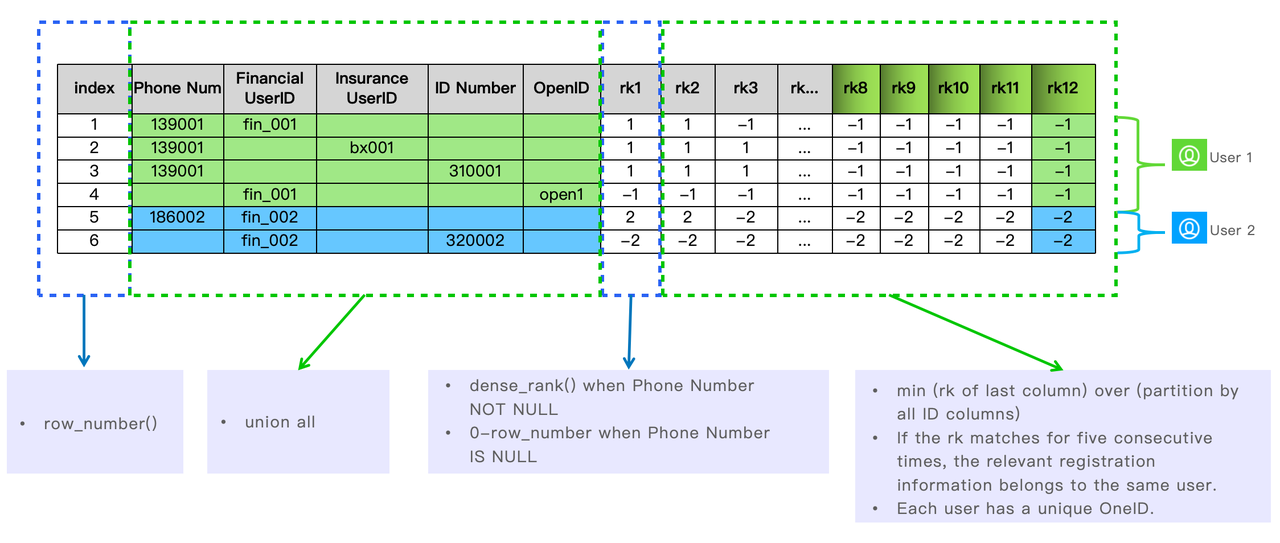
Has this ever occurred to you when you’ve got completely different consumer registration programs on your services? You would possibly acquire the e-mail of UserID A from one product webpage, and later the social safety variety of UserID B from one other. You then discover out that UserID A and UserID B truly belong to the identical particular person as a result of they go by the identical cellphone quantity.
That is why OneID arises as an thought. It’s to pool the consumer registration data of all enterprise strains into one massive desk in Apache Doris, type it out, and ensure that one consumer has a singular OneID.
That is how they work out which registration data belongs to the identical consumer leveraging the capabilities in Apache Doris.
Tagging Companies
This CDP accommodates data of 500 million prospects, which come from over 500 supply tables and are connected to over 2000 tags in complete.
By timeliness, the tags will be divided into real-time tags and offline tags. The true-time tags are computed by Apache Flink and written into the flat desk in Apache Doris, whereas the offline tags are computed by Apache Doris as they’re derived from the consumer attribute desk, enterprise desk, and consumer conduct desk in Doris. Right here is the corporate’s greatest apply in knowledge tagging:
1. Offline Tags
In the course of the peaks of information writing, a full replace would possibly simply trigger an OOM error given their large knowledge scale. To keep away from that, they make the most of the INSERT INTO SELECT perform of Apache Doris and allow partial column replace. It will reduce down reminiscence consumption by loads and preserve system stability throughout knowledge loading.
set enable_unique_key_partial_update=true;
insert into tb_label_result(one_id, labelxx)
choose one_id, label_value as labelxx
from .....2. Actual-Time Tags
Partial column replace can be out there for real-time tags since even real-time tags are up to date at completely different paces. All that’s wanted is to set partial_columns to true.
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:id,stability,last_access_time" -T /tmp/take a look at.csv http://127.0.0.1:48037/api/db1/user_profile/_stream_load3. Excessive-Concurrency Level Queries
With its present enterprise dimension, the corporate is receiving question requests for tags at a concurrency stage of over 5000 QPS. They use a mix of methods to ensure excessive efficiency. Firstly, they undertake Prepared Statement for pre-compilation and pre-execution of SQL. Secondly, they fine-tune the parameters for Doris Backend and the tables to optimize storage and execution. Lastly, they allow row cache as a complement to the column-oriented Apache Doris.
disable_storage_row_cache = false
storage_page_cache_limit=40%
enable_unique_key_merge_on_write = true
store_row_column = true
light_schema_change = true
4. Tag Computation (Be part of)
In apply, many tagging companies are applied by multi-table joins within the database. That always includes greater than 10 tables. For optimum computation efficiency, they undertake the colocation group technique in Doris.
Buyer Grouping
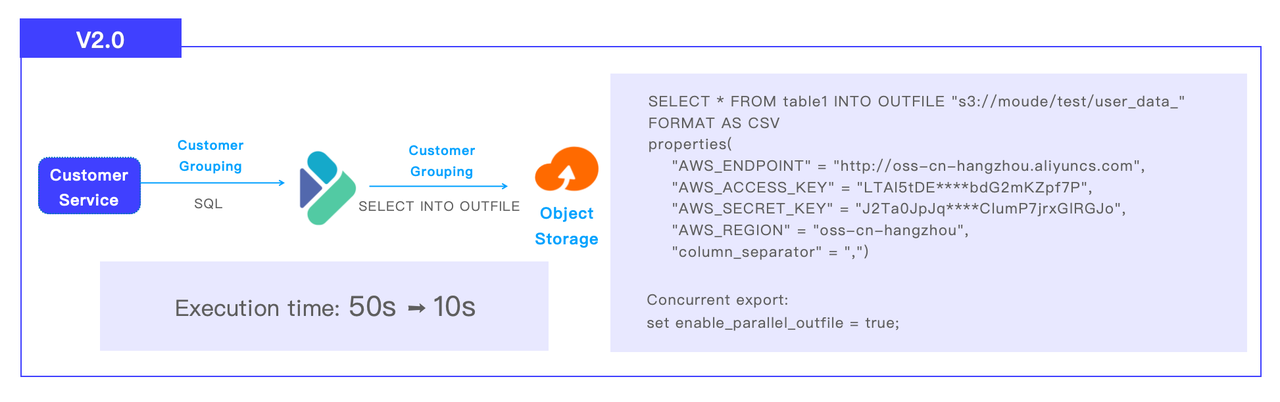
The shopper grouping pipeline in CDP 2.0 goes like this: Apache Doris receives SQL from customer support, executes the computation, and sends the end result set to S3 object storage through SELECT INTO OUTFILE. The corporate has divided its prospects into 1 million teams. The shopper grouping activity that used to take 50 seconds in Impala to complete now solely wants 10 seconds in Doris.
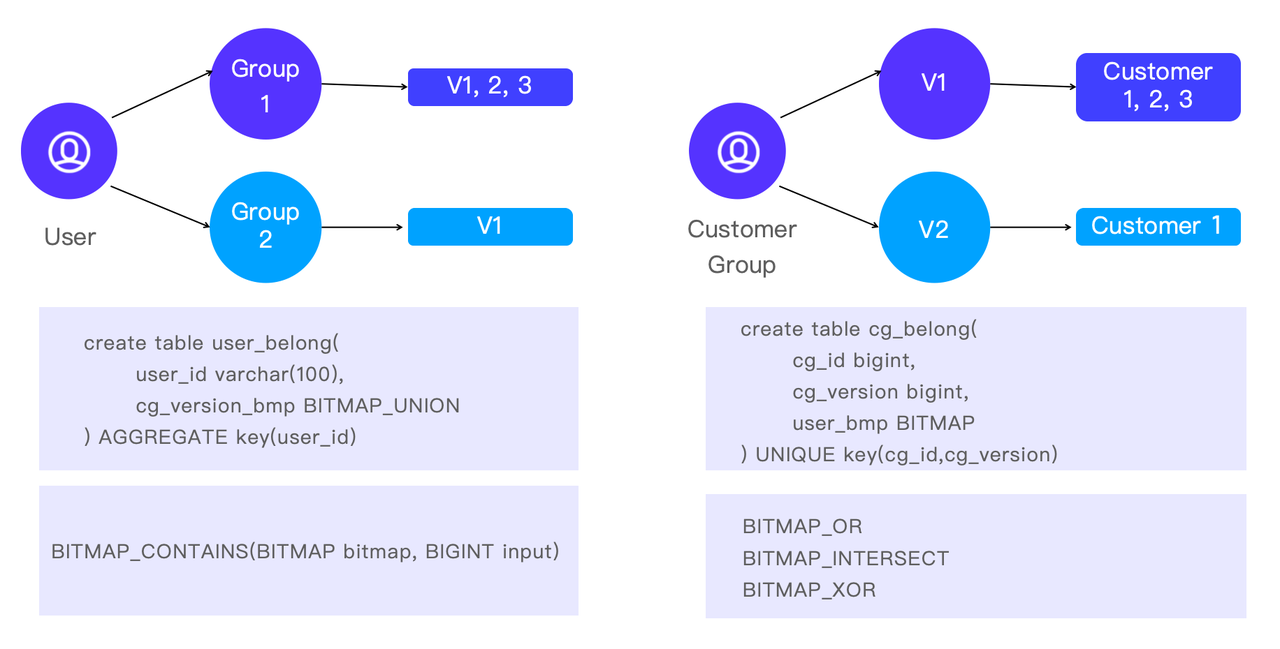
Other than grouping the purchasers for extra fine-grained evaluation, generally they do evaluation in a reverse path. That’s, to focus on a sure buyer and discover out to which teams he/she belongs. This helps analysts perceive the traits of consumers in addition to how completely different buyer teams overlap.
In Apache Doris, that is applied by the BITMAP capabilities: BITMAP_CONTAINS is a quick strategy to test if a buyer is a part of a sure group, and BITMAP_OR, BITMAP_INTERSECT, and BITMAP_XOR are the alternatives for cross-analysis.
Conclusion
From CDP 1.0 to CDP 2.0, the insurance coverage firm adopts Apache Doris, a unified knowledge warehouse, to exchange Spark+Impala+HBase+NebulaGraph. That will increase their knowledge processing effectivity by breaking down the info silos and streamlining knowledge processing pipelines. In CDP 3.0, they need to group their buyer by combining real-time tags and offline tags for extra diversified and versatile evaluation. The Apache Doris community and the VeloDB staff will proceed to be a supporting accomplice throughout this improve.





