
A lot has modified since I wrote the article An Introduction to BentoML: A Unified AI Application Framework, each within the common AI panorama and BentoML. Generative AI, Large Language Models, diffusion fashions, ChatGPT (Sora), and Gemma: these are in all probability probably the most talked about phrases over the previous a number of months in AI and the tempo of change is overwhelming. Amid these sensible AI breakthroughs, the hunt for AI deployment tools that aren’t solely highly effective but additionally user-friendly and cost-effective stays unchanged. For BentoML, it comes with a significant replace 1.2, which strikes in the direction of the exact same purpose.
On this weblog put up, let’s revisit BentoML and use a easy instance to see how we are able to leverage a few of the new instruments and functionalities offered by BentoML to construct an AI utility in manufacturing.
The instance utility I’ll construct is able to doing picture captioning, which includes producing a textual description for a picture utilizing AI. BLIP (Bootstrapping Language-Picture Pre-training) is a technique that improves these AI fashions by initially coaching on giant image-text datasets to know their relationship, after which additional refining this understanding with particular duties like captioning. The BLIP mannequin I’ll use within the sections beneath is Salesforce/blip-image-captioning-large. You should utilize another BLIP mannequin for this instance because the code implementation logic is identical.
A Fast Intro
Earlier than we delve deeper, let’s spotlight what BentoML brings to the desk, particularly with its 1.2 replace. At its core, BentoML is an open-source platform designed to streamline the serving and deployment of AI functions. This is a simplified workflow with BentoML 1.2:
- Mannequin wrapping: Use BentoML Service SDKs to wrap your machine studying mannequin in an effort to expose it as an inference endpoint.
- Mannequin serving: Run the mannequin by yourself machine, leveraging your individual assets (like GPUs) for mannequin inference via the endpoint.
- Straightforward deployment: Deploy your mannequin to a serverless platform BentoCloud.
For the final step, beforehand we wanted to manually construct a Bento (the unified distribution unit in BentoML which incorporates supply code, Python packages, and mannequin reference and configuration), then push and deploy it to BentoCloud. With BentoML 1.2, “Construct, Push, and Deploy” are actually consolidated right into a single command bentoml deploy. I’ll discuss extra in regards to the particulars and BentoCloud within the instance beneath.
Word: If you wish to deploy the mannequin in your individual infrastructure, you possibly can nonetheless try this by manually constructing a Bento, after which containerizing it as an OCI-compliant picture.
Now, let’s get began to see how this works in observe!
Organising the Setting
Create a digital atmosphere utilizing venv. That is really useful because it helps keep away from potential package deal conflicts.
python -m venv bentoml-new
supply bentoml-new/bin/activate
Set up all of the dependencies.
pip set up "bentoml>=1.2.2" pillow torch transformers
Constructing A BentoML Service
First, import the mandatory packages and use a relentless to retailer the mannequin ID.
from __future__ import annotations
import typing as t
import bentoml
from PIL.Picture import Picture
MODEL_ID = "Salesforce/blip-image-captioning-large"Subsequent, let’s create a BentoML Service. For variations previous to BentoML 1.2, we use abstractions referred to as “Runners” for mannequin inference. In 1.2, BentoML works off this Runner idea by integrating the functionalities of API Servers and Runners right into a single entity referred to as “Services.” They’re the important thing constructing blocks for outlining model-serving logic in BentoML.
Ranging from 1.2, we use the @bentoml.service decorator to mark a Python class as a BentoML Service in a file referred to as service.py. For this BLIP instance, we are able to create a Service referred to as BlipImageCaptioning like this:
@bentoml.service
class BlipImageCaptioning:
Throughout initialization, what we often do is load the mannequin (and different parts if essential) and transfer it to GPU for higher computation effectivity. In case you are unsure what perform or package deal to make use of, simply copy and paste the initialization code from the BLIP model’s Hugging Face repo. Right here is an instance:
@bentoml.service
class BlipImageCaptioning:
def __init__(self) -> None:
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration
# Load the mannequin with torch and set it to make use of both GPU or CPU
self.gadget = "cuda" if torch.cuda.is_available() else "cpu"
self.mannequin = BlipForConditionalGeneration.from_pretrained(MODEL_ID).to(self.gadget)
self.processor = BlipProcessor.from_pretrained(MODEL_ID)
print("Mannequin blip loaded", "gadget:", self.gadget)
The following step is to create an endpoint perform for consumer interplay via @bentoml.api. When utilized to a Python perform, it transforms that perform into an API endpoint that may deal with net requests.
This BLIP mannequin can take a picture and optionally some beginning textual content for captioning, so I outlined it this manner:
@bentoml.service
class BlipImageCaptioning:
...
@bentoml.api
async def generate(self, img: Picture, txt: t.Non-compulsory[str] = None) -> str:
if txt:
inputs = self.processor(img, txt, return_tensors="pt").to(self.gadget)
else:
inputs = self.processor(img, return_tensors="pt").to(self.gadget)
# Generate a caption for the given picture by processing the inputs via the mannequin, setting a restrict on the utmost and minimal variety of new tokens (phrases) that may be added to the caption.
out = self.mannequin.generate(**inputs, max_new_tokens=100, min_new_tokens=20)
# Decode the generated output right into a readable caption, skipping any particular tokens that aren't meant for show
return self.processor.decode(out[0], skip_special_tokens=True)
The generate technique inside the class is an asynchronous perform uncovered as an API endpoint. It receives a picture and an elective txt parameter, processes them with the BLIP mannequin, and returns a generated caption. Word that the principle inference code additionally comes from the BLIP model’s Hugging Face repo. BentoML right here solely helps you handle the input and output logic.
That’s all of the code! The whole model:
from __future__ import annotations
import typing as t
import bentoml
from PIL.Picture import Picture
MODEL_ID = "Salesforce/blip-image-captioning-large"
@bentoml.service
class BlipImageCaptioning:
def __init__(self) -> None:
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration
self.gadget = "cuda" if torch.cuda.is_available() else "cpu"
self.mannequin = BlipForConditionalGeneration.from_pretrained(MODEL_ID).to(self.gadget)
self.processor = BlipProcessor.from_pretrained(MODEL_ID)
print("Mannequin blip loaded", "gadget:", self.gadget)
@bentoml.api
async def generate(self, img: Picture, txt: t.Non-compulsory[str] = None) -> str:
if txt:
inputs = self.processor(img, txt, return_tensors="pt").to(self.gadget)
else:
inputs = self.processor(img, return_tensors="pt").to(self.gadget)
out = self.mannequin.generate(**inputs, max_new_tokens=100, min_new_tokens=20)
return self.processor.decode(out[0], skip_special_tokens=True)
To serve this mannequin domestically, run:
bentoml serve service:BlipImageCaptioning
The HTTP server is accessible at http://localhost:3000. You can interact with it using the Swagger UI.

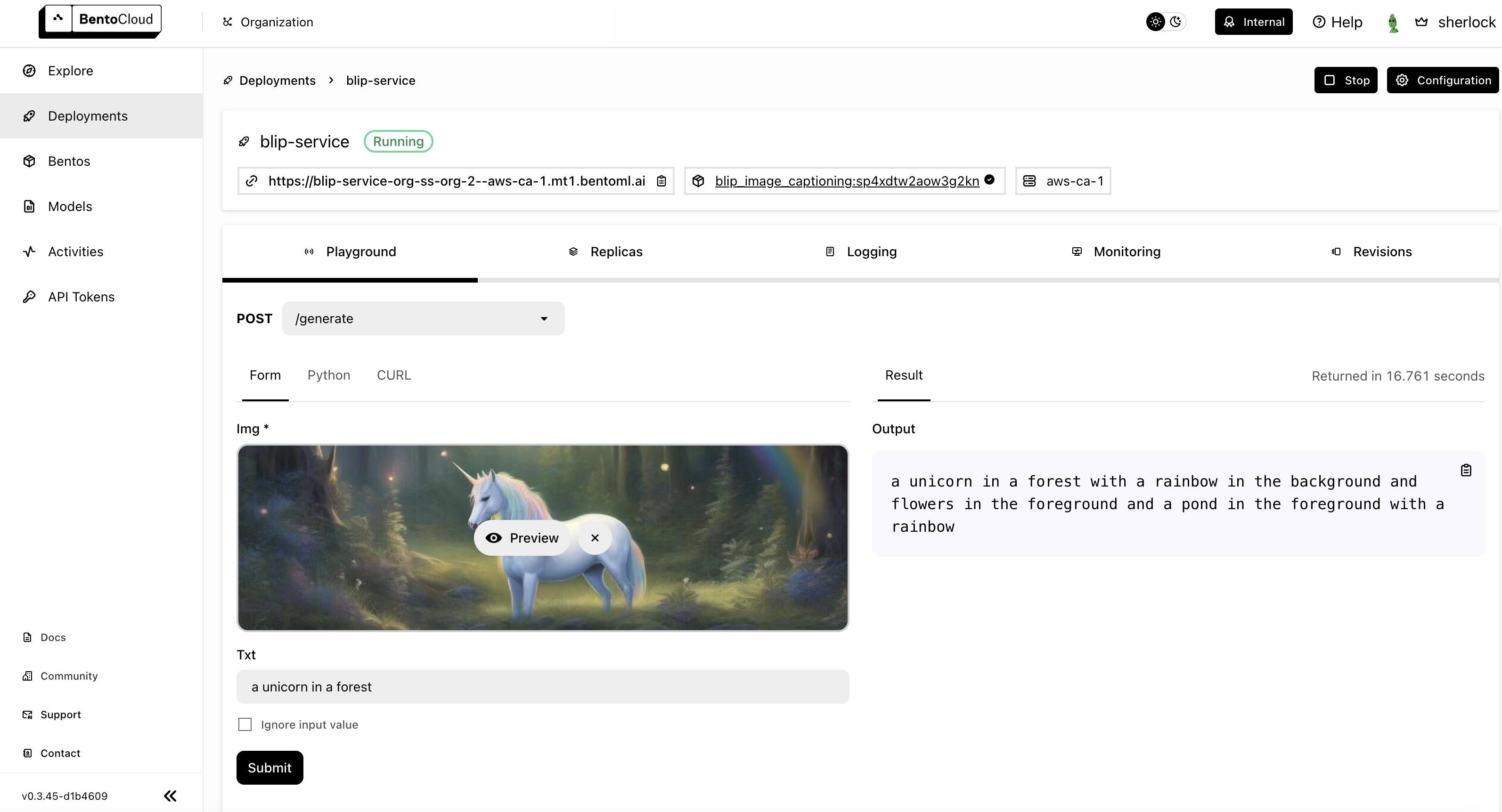
I uploaded the picture beneath (I created this picture with Steady Diffusion, and it was additionally deployed utilizing BentoML) and used the immediate textual content “a unicorn in a forest” for inference.

The picture caption output by the mannequin was : a unicorn in a forest with a rainbow within the background and flowers within the foreground and a pond within the foreground with a rainbow.
Native serving works correctly however there are various things we all the time want to contemplate for deploying AI functions in manufacturing, resembling infrastructure (particularly GPUs), scaling, observability, and cost-efficiency. That is the place BentoCloud is available in.
Deploying to BentoCloud
Explaining BentoCloud could require an unbiased weblog put up. This is an summary of what it provides and how one can leverage it to your machine studying deployment:
- Autoscaling for ML workloads: BentoCloud dynamically scales deployment replicas based mostly on incoming visitors, scaling all the way down to zero in periods of inactivity to optimize prices.
- Constructed-in observability: Entry real-time insights into your visitors, monitor useful resource utilization, observe operational occasions, and evaluate audit logs instantly via the BentoCloud console.
- Optimized infrastructure. With BentoCloud, the main focus shifts fully to code improvement because the platform manages all underlying infrastructure, making certain an optimized atmosphere to your AI functions.
To organize your BentoML Service for BentoCloud deployment, start by specifying the assets discipline in your Service code. This tells BentoCloud methods to allocate the right occasion kind to your Service. For particulars, see Configurations.
@bentoml.service(
assets={
"reminiscence" : "4Gi"
}
)
class BlipImageCaptioning:
Subsequent, create a bentofile.yaml file to outline the construct choices, which is used for constructing a Bento. Once more, when utilizing BentoCloud, you don’t must construct a Bento manually, since BentoML does this mechanically for you.
service: "service:BlipImageCaptioning"
labels:
proprietor: bentoml-team
undertaking: gallery
embody:
- "*.py"
python:
packages:
- torch
- transformers
- pillow
Deploy your Service to BentoCloud utilizing the bentoml deploy command, and use the -n flag to assign a customized title to your Deployment. Don’t overlook to log in beforehand.
bentoml deploy . -n blip-service
Deployment includes a collection of automated processes the place BentoML builds a Bento, after which pushes and deploys it to BentoCloud. You may see the standing displayed in your terminal.

All set! As soon as deployed, yow will discover the Deployment on the BentoCloud console, which supplies a complete interface, providing enhanced consumer expertise for interacting together with your Service.
Conclusion
BentoML 1.2 considerably simplifies AI deployment, enabling builders to simply carry AI fashions into manufacturing. Its integration with BentoCloud provides scalable, environment friendly options. In future weblog posts, I’ll reveal methods to construct extra production-ready AI functions for various situations. Blissful coding!





