
Within the quickly evolving world of enormous language fashions (LLMs), a brand new challenger has emerged that claims to outperform the reigning champion, OpenAI’s GPT-4. Anthropic, a comparatively new participant within the discipline of synthetic intelligence, has lately introduced the release of Claude 3, a strong language mannequin that is available in three completely different sizes: Haiku, Sonnet, and Opus.

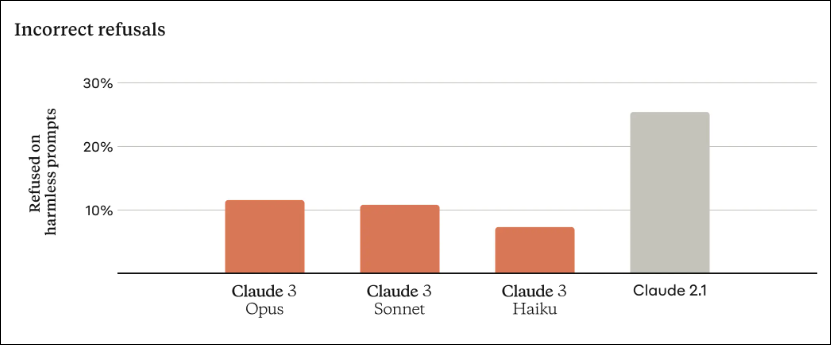
In comparison with earlier fashions, the brand new Claude 3 mannequin shows enhanced contextual understanding that finally ends in fewer refusals (as proven within the above picture). The corporate claims that the Claude 3 Opus mannequin rivals and even surpasses GPT-4 contemplating efficiency throughout numerous benchmarks. Consultants interact in full of life debates relating to the doable superiority of Claude 3 over GPT-4 because the pre-eminent language mannequin in the marketplace.
This complete evaluation offers with each fashions’ strengths, limitations, and real-world functions throughout numerous benchmarks.
Efficiency: A Nearer Look
Benchmarks and Scores
Anthropic cites benchmark scores to assist its declare that the Claude 3 Opus mannequin outperforms GPT-4. Anthropic cites benchmark scores to assist its declare that the Claude 3 Opus mannequin outperforms GPT-4. For example, within the GSM8K benchmark, which evaluates language fashions on their capability to grasp and cause about pure language, the Claude 3 Opus mannequin notably outperformed GPT-4, securing a rating of 95.0% in comparison with GPT-4’s 92.0%.
Nevertheless, it is vital to notice that this comparability was made towards the default GPT-4 mannequin, not the superior GPT-4 Turbo variant. When GPT-4 Turbo is factored into the equation, the tables flip: in the identical GSM8K check, GPT-4 Turbo scored a formidable 95.3%, edging out the Claude 3 Opus mannequin.
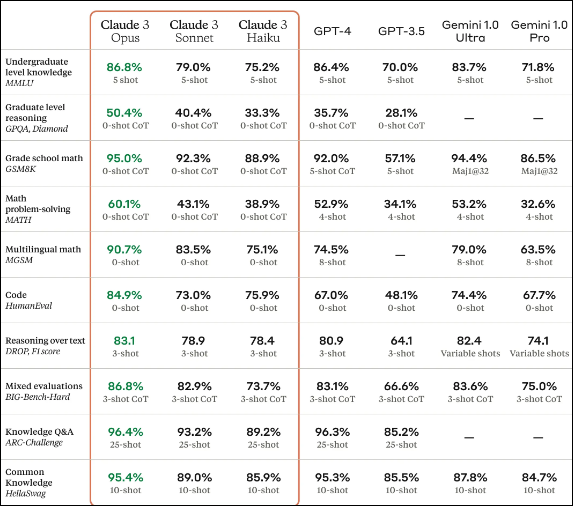
Just like GPT-4V, Claude 3 additionally comes with Imaginative and prescient assist and in addition creates benchmarks throughout, multilingual understanding, reasoning, and so forth. There are three fashions included on this Claude 3’s household: i.e. Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku. Sonnet is one in all three multi-modal fashions launched by Anthropic in text-only model and offers 2x the velocity of Claude 2 fashions for many workloads. Claude 3 Haiku is the quickest and most cost-effective mannequin that may simply course of a ten,000-token analysis paper in underneath 3 seconds whereas Opus delivers wonderful outcomes on evaluations like GPQA, MMLU, and MMMU, displaying fluency on probably the most tough duties like human-level comprehension.
Enter/Output Selection
One space the place GPT-4 holds a transparent benefit is its capability to course of a variety of enter and output codecs. GPT-4’s capabilities embody understanding numerous types of knowledge, together with textual content, code, visuals, and audio inputs. It generates exact outputs by comprehending and mixing this numerous info. Moreover, the GPT-4V variant can produce novel and distinctive photos by analyzing textual or visible prompts, making it a flexible software for professionals in fields necessitating visible content material creation.
In distinction, the Claude 3 mannequin is restricted to processing textual and visible inputs, producing solely textual outputs. Whereas it might probably extract insights from photos, and browse graphs, and charts, it can’t produce visible outputs like GPT-4V. Moreover, the Claude 3 Sonnet mannequin, whereas extra superior than GPT-3.5, continues to be weaker than GPT-4 by way of total capabilities.
Immediate Following and Process Completion
Each fashions display spectacular capabilities when following prompts and finishing duties however with slight variations. The Claude 3 Opus mannequin has extra superior prompt-following abilities than GPT-4, producing 10 logical outputs by following a given immediate, whereas GPT-4 can solely generate 9. Nevertheless, the Claude 3 Sonnet mannequin lags, producing solely 7 logical sentences in the identical check.
This means that whereas the top-tier Claude 3 Opus excels at immediate following, the extra accessible Sonnet mannequin falls brief in comparison with GPT-4. Moreover, GPT-4’s efficiency in process completion and reasoning could differ relying on the particular process and context.
Accessibility and Value
Relating to accessibility and price, GPT-4 has a slight edge over Claude 3. Whereas OpenAI affords free entry to the GPT-3.5 mannequin, accessing GPT-4 requires an OpenAI Plus subscription, which entails prices per thirty days. This subscription grants customers entry to the GPT-4 mannequin and its superior options, akin to customized GPTs and net search capabilities.
Then again, to expertise the Claude 3 Sonnet mannequin, customers merely must create an account on Anthropic’s official net chatbot interface, which is accessible in 159 international locations. Nevertheless, to entry the extra highly effective Claude 3 Opus mannequin, customers will need to have a paid Claude Professional subscription from Anthropic.
The Verdict: A Nuanced Comparability
Anthropic’s Claude 3 Opus mannequin and OpenAI’s GPT-4 are highly effective language fashions with distinct strengths. Whereas Anthropic claims that Claude 3 Opus outperforms GPT-4 in sure duties, the introduction of GPT-4 Turbo complicates the comparability. GPT-4 Turbo appears to have an total edge, scoring increased on benchmarks like GSM8K. Nevertheless, Claude 3 Opus excels at immediate following, producing extra logical outputs when given prompts. The selection between the 2 fashions might also rely upon accessibility and price components, with Claude 3 providing extra reasonably priced choices for accessing its lower-tier fashions.
When it comes to total efficiency, GPT-4 Turbo seems to have a slight benefit over Claude 3 Opus. It achieves increased scores on a number of benchmarks designed to check language fashions’ capabilities in numerous duties. These benchmarks consider components like coherence, factual accuracy, and reasoning skills. Nevertheless, it is vital to notice that no single benchmark can present an entire image of a mannequin’s efficiency, and completely different benchmarks could favor completely different strengths.
Then again, Claude 3 Opus stands out in its capability to comply with prompts extra intently and generate outputs which are extra logically in keeping with the given directions. This may be notably invaluable in situations the place exact adherence to prompts is essential, akin to in task-specific functions.
Finally, the choice between Claude 3 and GPT-4 will rely upon the particular wants and priorities of the consumer.
The Way forward for Language Fashions
As the sphere of synthetic intelligence continues to evolve quickly, the competitors between these highly effective language fashions will seemingly intensify. Whereas Claude 3 has undoubtedly made a powerful entry into the market, GPT-4’s versatility and efficiency make it a formidable opponent.
The continual progress in language fashions and AI assistants holds immense benefits for customers. As these applied sciences change into extra broadly accessible, they possess the potential to alter numerous sectors and empower people in addition to companies.
Regardless of the mannequin that finally leads the pack, one certainty stays: the period of enormous language fashions has arrived, and their affect on our each day lives {and professional} endeavors will solely intensify.
Conclusion
The battle between Claude 3 and GPT-4 is just the start of what guarantees to be an ongoing arms race within the improvement of more and more refined and succesful massive language fashions. The world of synthetic intelligence is repeatedly advancing as corporations like Anthropic and OpenAI deliver innovation. Nevertheless, making definitive comparisons or superiority claims requires cautious consideration. Whereas benchmarks provide invaluable insights, real-world functions could reveal complexities that these metrics can’t seize absolutely. Furthermore, the state of affairs shifts quickly with new developments like GPT-4 Turbo rapidly altering the enjoying discipline. A balanced perspective is important when evaluating these complicated language fashions.





