In DevOps, each monitoring and observability are crucial.
As a result of it helps you to preserve system reliability, diagnose issues, and improve efficiency, successfully and effectively.
For DevOps, that is the essence of monitoring and observability.
- Monitoring is for computer systems; observability is for individuals.
- Monitoring is about amassing knowledge; observability is about making sense of it.
- Observability is about “why,” whereas monitoring is about “what.”
- Monitoring is critical, however observability is indispensable.
- On the planet of techniques, monitoring is the start line, however observability is the vacation spot.
- Observability is the important thing to unlocking the mysteries of distributed techniques.
How Prime Digital Merchandise Are Using Observability and Monitoring for Engineering Excellence?
Observability and monitoring have grow to be important parts in making certain the reliability, efficiency, and scalability of digital merchandise.
Right here’s how prime digital merchandise are using observability and monitoring.
Netflix
Streamlining eBPF Efficiency Optimization
Netflix just lately introduced the discharge of bpftop.
bpftop gives a dynamic real-time view of working eBPF applications. It shows the typical runtime, occasions per second, and estimated whole CPU % for every program.
This software reduces overhead by permitting efficiency statistics solely when in use.
With out bpftop, optimization duties would demand handbook computations, needlessly complicating the method.
However with bpftop, it’s simpler. You possibly can see the place you’re ranging from, make issues higher, and verify if they really acquired higher, all with out the additional trouble. (Source)
Improved Alerting With Atlas Streaming Eval
Netflix shifted its alerting system structure from conventional polling-based strategies to real-time streaming analysis.
This transition was prompted by scalability points when the variety of configured alerts dramatically elevated, inflicting delays in alert notifications.

By leveraging streaming analysis, Netflix overcame the constraints of its time-series database, Atlas, and improved scalability whereas sustaining reliability.
Key outcomes embrace accommodating a 20X enhance in question quantity, stress-free restrictions on excessive cardinality queries, and enhancing software well being monitoring with correlations between SLI metrics and customized metrics derived from log knowledge.
This shift opens doorways to extra actionable alerts and superior observability capabilities, although it requires overcoming challenges in debugging and aligning the streaming path with database queries.
General, the transition showcases a big development in Netflix’s observability infrastructure. (Source)
Constructing Netflix’s Distributed Tracing Infrastructure
Edgar, a distributed tracing infrastructure geared toward enhancing troubleshooting effectivity for streaming companies.
Previous to Edgar, engineers at Netflix confronted challenges in understanding and resolving streaming failures as a result of lack of context offered by conventional troubleshooting strategies involving metadata and logs from numerous microservices.
Edgar addresses this by offering complete distributed tracing capabilities, permitting for the reconstruction of streaming periods via the identification of session IDs.
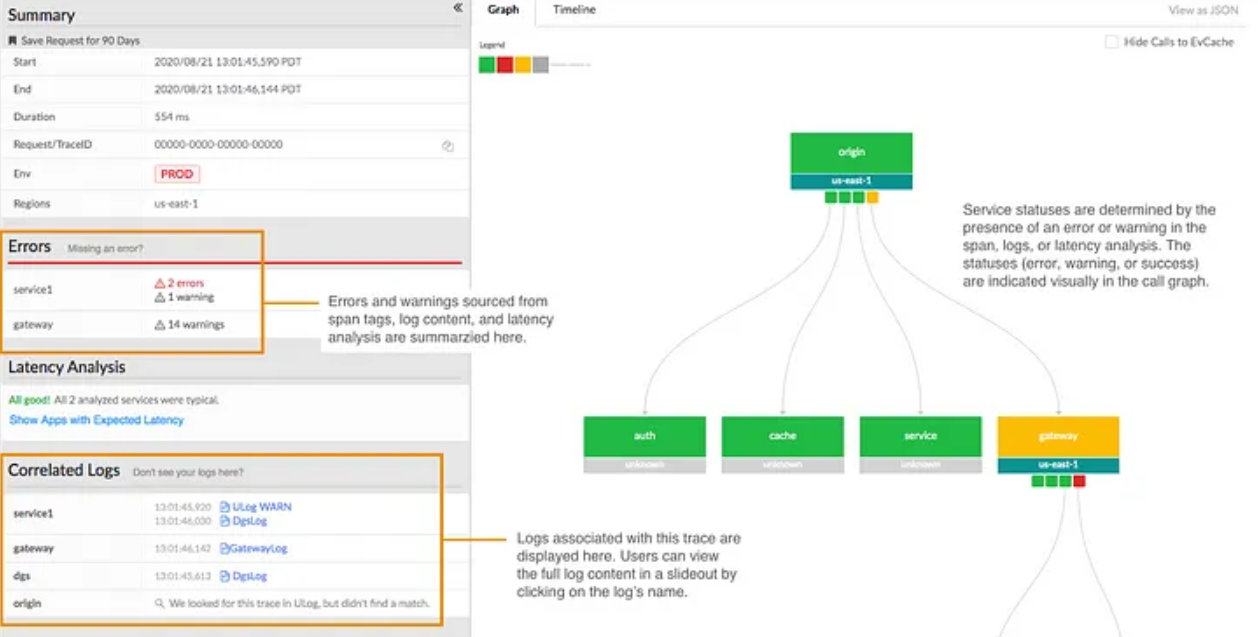
Leveraging Open-Zipkin for tracing and Mantis for stream processing, Edgar permits the gathering, processing, and storage of traces from numerous microservices.
Key parts of Edgar embrace hint instrumentation for context propagation, stream processing for knowledge sampling, and storage optimization for cost-effective knowledge retention.
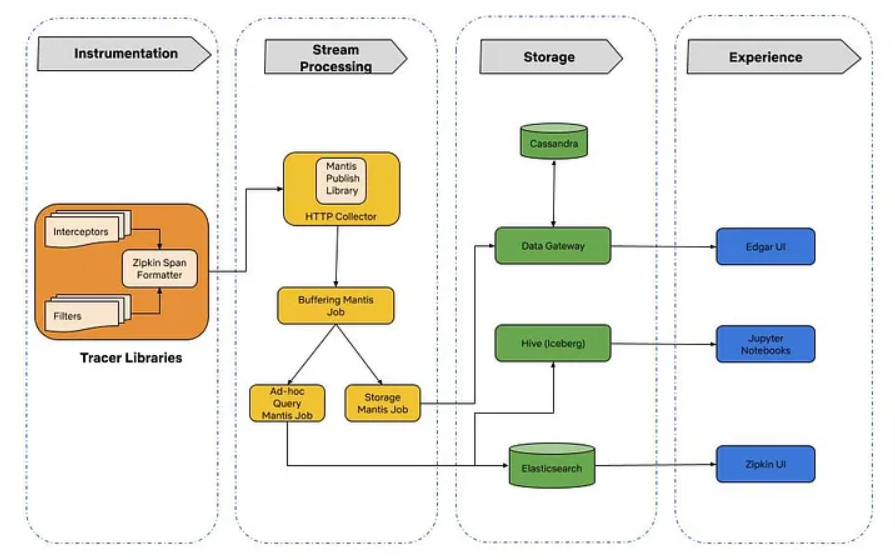
By means of a hybrid head-based sampling strategy and storage optimization methods similar to using cheaper storage choices and using higher compression methods, Edgar optimizes useful resource utilization whereas making certain environment friendly troubleshooting.
Moreover, Edgar’s hint knowledge serves a number of use circumstances past troubleshooting, together with software well being monitoring, resiliency engineering, regional evacuation planning, and infrastructure price estimation for A/B testing.
In essence, Edgar considerably improves engineering productiveness by offering a streamlined and efficient methodology for troubleshooting streaming failures at scale. (Source)
Uber
Observability at Scale: Constructing Uber’s Alerting Ecosystem
Uber’s alerting ecosystem is a crucial element in sustaining the steadiness and scalability of its 1000’s of microservices.
The Observability staff has developed two main alerting techniques: uMonitor, which focuses on metrics-based alerts, and Neris, which handles host-level infrastructure alerts.
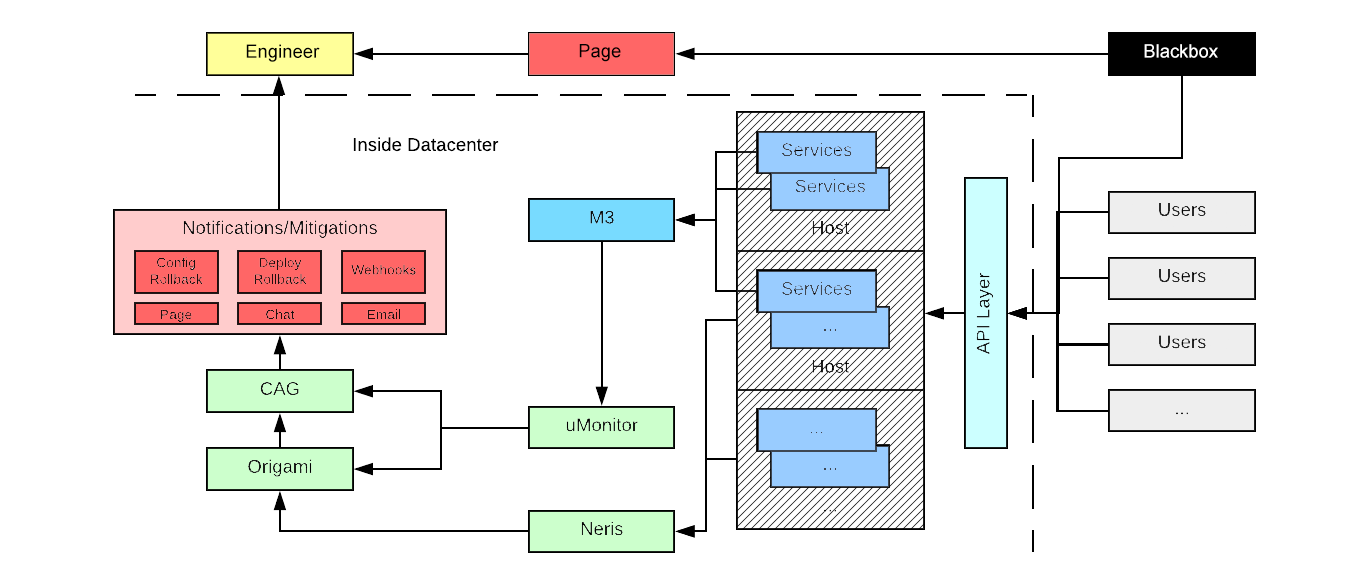
uMonitor operates on a versatile platform, permitting for simple alert administration and numerous use circumstances, whereas Neris executes alert checks instantly on hosts to effectively deal with high-resolution, high-cardinality metrics.
Dealing with the problem of excessive cardinality is central to Uber’s alerting strategy.
Origami, the deduplication and notification engine, assists in managing alerts by consolidating notifications and permitting for alert aggregation primarily based on numerous standards similar to metropolis, product, or app model.
This helps in decreasing noise and offering related alerts to engineers.
General, Uber’s alerting ecosystem is tailor-made to deal with the size and complexity of its infrastructure, with a deal with flexibility, scalability, and relevance of notifications. (Source)
Uber’s Large Knowledge Observability and Chargeback Platform
Uber’s knowledge infrastructure consists of all kinds of compute engines, execution options, and storage options.
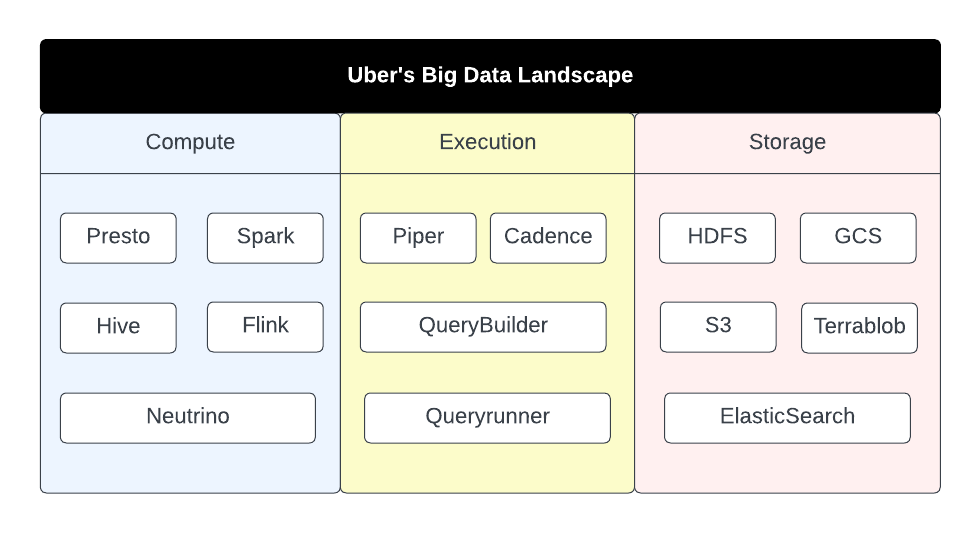
With such a fancy and numerous knowledge infrastructure, it’s fairly difficult to supply stakeholders with a holistic view of efficiency and useful resource consumption throughout numerous compute engines and storage options.
And that is when DataCentral comes into the image.
It’s a complete platform to supply customers with important insights into massive knowledge purposes and queries.
DataCentral helps knowledge platform customers by providing detailed info on workflows and apps, enhancing productiveness, and decreasing debugging time.
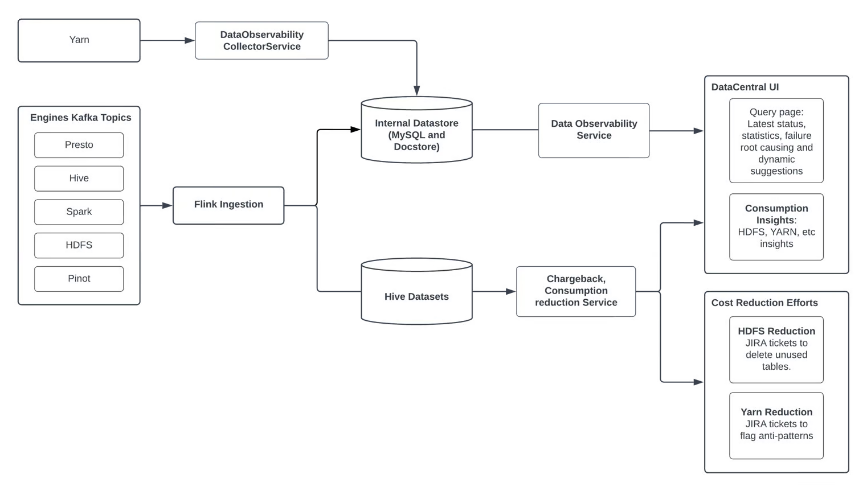
The next are the important thing options of DataCentral.
Observability
It gives granular insights into efficiency developments, prices, and degradation alerts for large knowledge jobs.
Moreover, DataCentral affords historic developments for metrics like prices, length, effectivity, knowledge learn/written, and shuffle, enabling quicker detection and debugging of purposes.
Chargeback
It tracks metrics and useful resource utilization for large knowledge instruments and engines similar to Presto, Yarn, HDFS, and Kafka, permitting stakeholders to grasp prices at numerous granularities like person, pipeline, software, schedule, and queue degree.
Consumption Discount Applications
DataCentral powers price discount initiatives by offering insights into costly pipelines, constantly failing workloads, and pointless computing.
Contactless
A system geared toward effectively troubleshooting failed queries and purposes by enhancing error discoverability, figuring out root causes, and offering user-friendly explanations and ideas.
It matches exception traces towards guidelines set by engine groups to floor related messages. (Source)
Fb
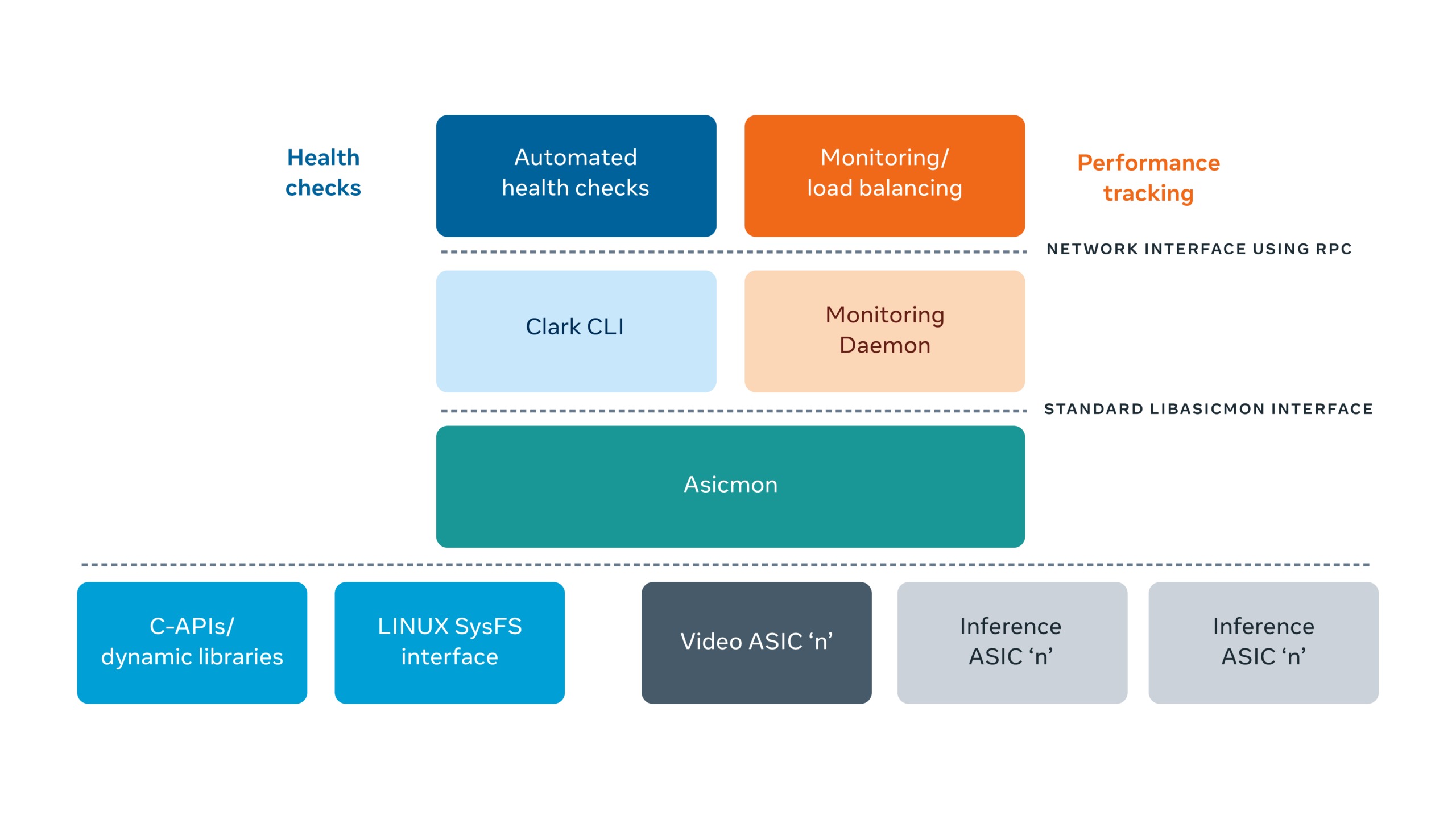
Asicmon: A Platform Agnostic Observability System for AI Accelerators
Accelerators are like specialised instruments for particular jobs, similar to AI duties or video work.
They’re tremendous useful in making issues quicker and extra energy-efficient, particularly in Fb’s knowledge facilities.
However dealing with all these completely different instruments effectively at an enormous scale is hard.
To deal with these obstacles, Fb launched three progressive instruments.
Asicmon (ASIC Monitoring)
This scalable observability framework abstracts customized interfaces of accelerators, providing a standardized interface to inner instruments.
Asicmon facilitates load balancing, efficiency monitoring, and automatic well being checks for the multitude of accelerators deployed throughout Fb knowledge facilities.
Asimov
It’s a bespoke specification language streamlining the event and speedy prototyping of recent accelerators.
By decreasing the onboarding time for a brand new accelerator from a month to below per week, Asimov considerably accelerates the innovation cycle.
Atrace
An accelerator tracing answer that remotely collects traces on manufacturing servers.
Atrace permits in-depth inspection of accelerator techniques, offering actionable hint summaries and analyses.
In an preliminary deployment, Atrace helped slender a ten p.c efficiency hole between Caffe2 and PyTorch implementations of a big AI mannequin.
Right here is the diagram of how Asicmon acts as a bridge between particular person accelerator drivers and the remainder of the interior monitoring software program. (Source)