
Within the evolving panorama of software program improvement, the controversy between utilizing REST and GraphQL for constructing microservices is changing into more and more related. Each applied sciences have their proponents and critics, however on the subject of the precise wants of microservices architectures, GraphQL emerges because the clear front-runner. Here is why.
Understanding the RESTful Considerations
Reputation vs. Limitations
Whereas REST has been the go-to API fashion for a few years, lauded for its simplicity and common applicability, its limitations turn out to be obviously obvious within the context of microservices. These limitations embrace:
- Over-fetching of information.
- A number of HTTP requests for associated knowledge.
- Advanced versioning methods.
Such points can impede the efficiency and scalability of microservices architectures.
Over-Fetching of Information
REST APIs are designed to return a set set of information, which frequently leads to over-fetching. This redundancy is especially problematic in cellular networks, the place each further byte of information can result in slower purposes and degraded consumer experiences.
For instance:
Think about we have now a REST API endpoint /API/consumer/{userId}, which returns the next knowledge for a consumer:

In situations the place cellular apps solely require particular consumer particulars like identify and electronic mail for a profile overview, fetching complete consumer knowledge means over-fetching.
This extra knowledge utilization could be expensive for customers with restricted knowledge plans and end in slower app efficiency and degradation of consumer expertise.
Latency and the N+1 Downside
Microservices usually require knowledge which are unfold throughout a number of companies.
Suppose you have got an eCommerce utility the place the Order area handles Product, Buyer, Order, and Return entities, and the Inventory area manages Product, Inventory, Warehouse, and Supply entities. A standard operation is perhaps to show order particulars together with the present inventory standing for every product within the order.
For instance we have now an Order Microservice and a Inventory microservice to deal with Orders and Shares.
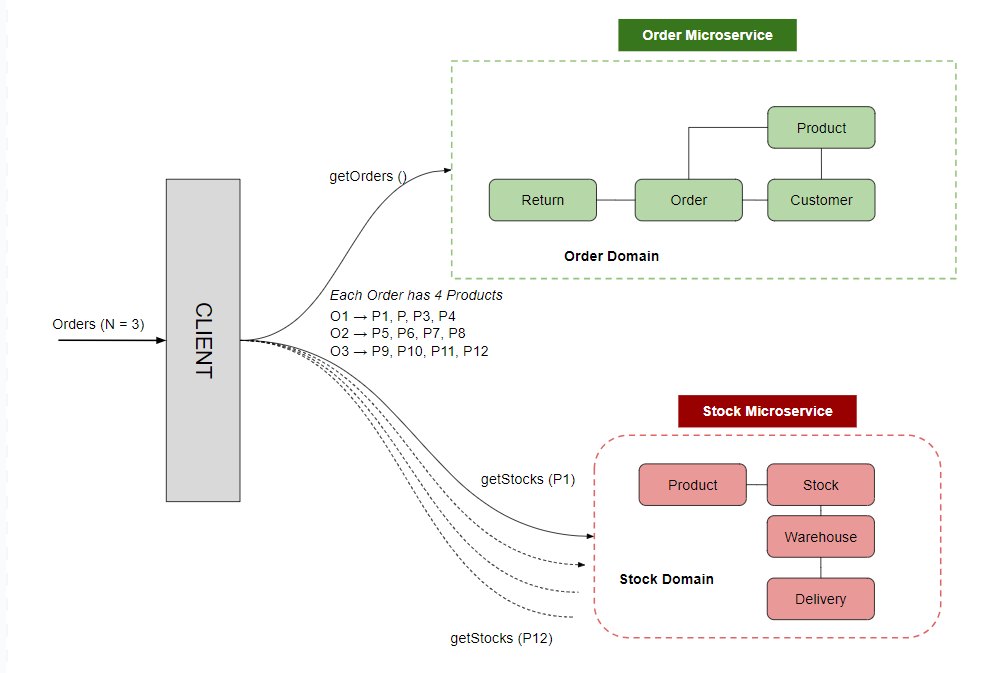
If a buyer has positioned 3 orders (N=3), and every order comprises 4 totally different merchandise. To show the order particulars together with the inventory standing for every product, the applying initially makes 1 request to fetch the orders. Then, for every product in every order, it makes extra requests to the Inventory microservice to retrieve inventory info. This leads to 1 preliminary request + 12 subsequent requests (3 orders * 4 merchandise per order), summing as much as 13 API calls. This multiplicative enhance in requests results in greater latency as a result of a number of round-trip occasions (RTT) and elevated load on the community and servers, embodying the N+1 downside.
Versioning Challenges
Sustaining REST APIs over time entails advanced versioning methods, akin to introducing new endpoints or embedding model numbers within the API path. This will result in bloat and confusion, complicating the event and consumption of APIs.
The GraphQL Benefit
Area-Pushed Design
Microservices thrive on a domain-driven design, the place every service is constructed round a selected enterprise functionality. GraphQL’s schema-centric method aligns completely with this, enabling a extra organized and coherent construction for microservices.
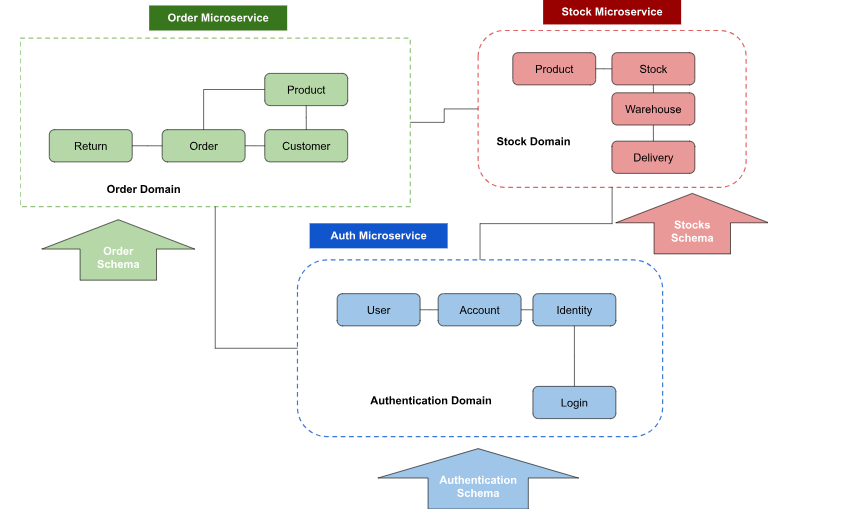
Unified Schema
In a microservices structure, every service could have its personal schema, representing a portion of the enterprise area. GraphQL stands out by permitting these schemas to be mixed or “stitched” collectively, presenting a unified interface to purchasers. Which means that purchasers can question knowledge from a number of companies in a single request, drastically decreasing the complexity and variety of community calls.
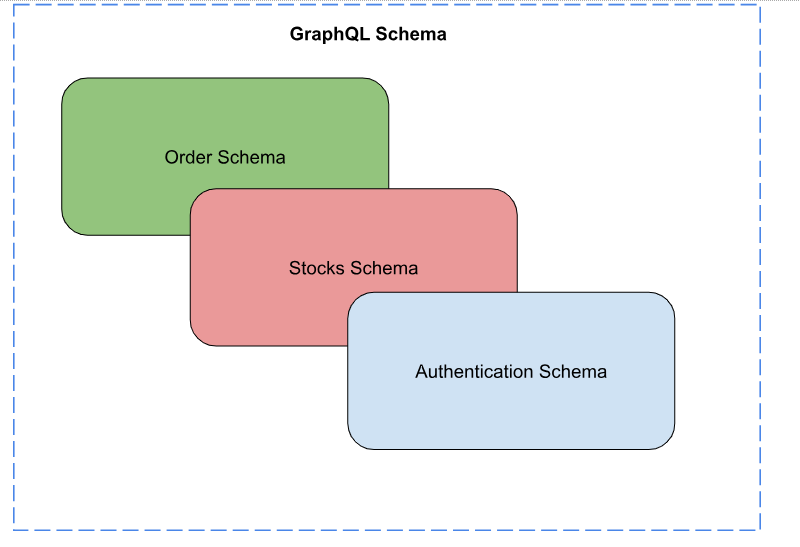
Fixing the N+1 Downside
GraphQL’s means to fetch knowledge with a single request, no matter what number of underlying companies must be known as, straight addresses the N+1 problem inherent in REST architectures. This not solely improves efficiency but additionally simplifies client-side knowledge fetching logic.
For the N + 1 downside described earlier, if the companies assist GraphQL, it may be used to fetch nested knowledge in a single question, successfully fixing the N+1 downside.
Effectivity and Efficiency
By permitting purchasers to specify precisely what knowledge they want, GraphQL eliminates over-fetching and under-fetching points frequent in REST APIs. This results in extra environment friendly knowledge retrieval, decreased bandwidth utilization, and quicker purposes, that are notably noticeable in cellular environments.
Within the earlier state of affairs the place cellular apps solely require particular consumer particulars like identify and electronic mail for a profile overview, purchasers can request simply identify and electronic mail alone.
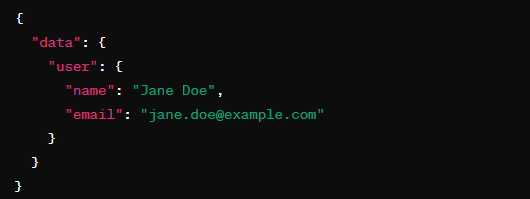
Simplified Versioning
Not like REST, GraphQL reduces the necessity for versioning by permitting new fields and kinds to be added to the schema with out impacting current queries. This ahead compatibility signifies that purchasers and servers can evolve extra easily over time.
GraphQL stands at present as a mature expertise that addresses particular wants in fashionable net improvement that aren’t totally met by conventional REST APIs. Its design promotes effectivity, flexibility, and developer productiveness. Wanting forward, the way forward for GraphQL is vibrant, with community-driven efforts targeted on addressing its present limitations, notably round safety, efficiency, and standardization. As these efforts bear fruit, GraphQL’s adoption is predicted to widen, consolidating its place as a key expertise within the API panorama.





